基于深度学习的手写数字识别
数据准备:MNIST手写数字数据集,可以到官网下载,也可从其他地方下载。
任务:使用深度学习对 MNIST 手写数字数据集完成手写数字(0~9)的分类, 首先使用LeNet网络模型在MNIST数据集上得到一个Baseline的准确度, 在此基础上尝试调整模型结构将准确度提升到99.5%以上(四舍五入不算,如类似99.45%不算)。
不限框架,Pytorch 、 Tensorflow 、 Keras 或者 飞桨 等均可。
参考:https://zhuanlan.zhihu.com/p/544161254
摘要
本次实验使用了 Pytorch 作为深度学习框架,并使用 matplotlib 作为可视化工具,实现了一个卷积神经网络(Convolutional Neural Network,CNN)对手写数字(MNIST数据集)进行分类的过程。
概述
MNIST是一个手写数字的图像数据集,其中包含了60000张训练图像和10000张测试图像。这些图像是由真实的手写数字扫描而来,图像分辨率为28x28像素,每个像素的灰度值介于0和255之间。MNIST数据集是机器学习领域的经典数据集之一,它被�广泛用于图像分类和模式识别等任务的研究和评估。
PyTorch是一个基于Python的开源深度学习框架,它提供了一系列工具和接口,可以方便地构建、训练和部署深度学习模型。PyTorch的优势在于它具有动态图的特性,这使得模型的构建和调试变得更加灵活和直观。此外,PyTorch还提供了许多预训练的模型和数据集,可以帮助用户更快地实现自己的深度学习应用。
在使用PyTorch进行深度学习任务时,用户需要定义一个模型的结构、损失函数和优化器,并对数据进行预处理和加载。然后,用户可以使用训练数据对模型进行训练,并使用测试数据进行验证和评估。PyTorch提供了许多工具和接口,可以方便地进行这些操作,并且具有高效的计算性能。
我的工作
为了减少第三方库的依赖,我使用了 Pytorch 作为深度学习框架,并使用 matplotlib 作为可视化工具。
本次实验需要导入以下依赖库:
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
from torchvision.transforms import Compose
import matplotlib.pyplot as plt
设定超参数
这里设定了一些超参数,用于控制训练过程。
train_batch_size: int = 256 # 训练集的batch_size
test_batch_size: int = 100 # 测试集的batch_size
learning_rate: float = 0.06 # 学习率
epoch: int = 100 # 迭代次数
random_seed: int = 2 # 随机种子
设置推理设备
如果有可用的GPU,就使用GPU,可以加快训练速度。
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
if torch.cuda.is_available():
torch.backends.cudnn.benchmark = True # 自动寻找最优算法
device = torch.device('cuda')
torch.cuda.empty_cache() # 释放显存
torch.cuda.manual_seed_all(random_seed) # 为gpu提供随机数
else:
device = torch.device('cpu')
torch.manual_seed(random_seed) # 为cpu提供随机数
print(f'Use device:{device}')
定义 Compose 对象
Compose 对象可以将多个转换组合在一起,例如将 ToTensor 和 Normalize 组合在一起,可以将图像转换为张量并进行标准化,方便后续调用。
# 构建 compose 类的实例,包含转张量和标准化
train_transform: Compose = Compose([
transforms.RandomAffine(degrees=0, translate=(0.1, 0.1)), # 对照片进行随机平移
transforms.RandomRotation((-10, 10)), # 随机旋转
transforms.ToTensor(), # 转张量
transforms.Normalize((0.1307,), (0.3081,)) # 标准化 (均值, 标准差)
])
# 标准化 (均值, 标准差)
test_transform: Compose = Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
加载数据集
这里使用了 torchvision 中的 datasets 模块,可以方便地加载数据集。
并载入到 DataLoader 对象,方便后续对数据集进行批量处理。
# 加载数据集,启用了自动下载
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=train_transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=test_transform)
# 构建数据加载器
train_loader = DataLoader(dataset=train_dataset, batch_size=train_batch_size, shuffle=True, pin_memory=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=test_batch_size, shuffle=False, pin_memory=True)
构建残差神经网络
class ResidualBlock(nn.Module):
"""残差神经网络"""
# 需要保证输出和输入通道数x一样
def __init__(self, channels):
super().__init__()
self.channels = channels
# 3*3 卷积核,保证图像大小不变将padding设为1
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(channels, channels, kernel_size=1)
def forward(self, x):
# 激活
y = F.relu(self.conv1(x))
y = self.conv2(y)
# 先求和 后激活
z = self.conv3(x)
return F.relu(z + y)
构建主神经网络
class Net(nn.Module):
def __init__(self):
super().__init__()
# 卷积层
self.conv1 = nn.Conv2d(1, 32, kernel_size=5, padding=2)
self.conv2 = nn.Conv2d(32, 64, kernel_size=5, padding=2)
self.conv3 = nn.Conv2d(64, 128, kernel_size=5, padding=2)
self.conv4 = nn.Conv2d(128, 192, kernel_size=5, padding=2)
# 残差神经网络层,其中已经包含了relu
self.rblock1 = ResidualBlock(32)
self.rblock2 = ResidualBlock(64)
self.rblock3 = ResidualBlock(128)
self.rblock4 = ResidualBlock(192)
# BN层,归一化,使数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定
self.bn1 = nn.BatchNorm2d(32)
self.bn2 = nn.BatchNorm2d(64)
self.bn3 = nn.BatchNorm2d(128)
self.bn4 = nn.BatchNorm2d(192)
# 最大池化,一般最大池化效果都比平均池化好些
self.mp = nn.MaxPool2d(2)
# 全连接层
self.fc1 = nn.Linear(192 * 7 * 7, 256) # 线性
self.fc6 = nn.Linear(256, 10) # 线性
def forward(self, x):
in_size = x.size(0)
# channels:1-32 w*h:28*28
x = self.conv1(x)
x = self.bn1(x)
x = F.relu(x)
x = self.rblock1(x)
# channels:32-64 w*h:28*28
x = self.conv2(x)
x = F.relu(x)
x = self.bn2(x)
x = self.rblock2(x)
# 最大池化,channels:64-64 w*h:28*28->14*14
x = self.mp(x)
# channels:64-128 w*h:14*14
x = self.conv3(x)
x = self.bn3(x)
x = F.relu(x)
x = self.rblock3(x)
# channels:128-192 w*h:14*14
x = self.conv4(x)
x = self.bn4(x)
x = F.relu(x)
x = self.rblock4(x)
# 最大池化,channels:192-192 w*h:14*14->7*7
x = self.mp(x)
x = x.view(in_size, -1) # 展开成向量
x = F.relu(self.fc1(x)) # 使用relu函数来激活
return self.fc6(x)
实例化模型
构建模型实例并构建优化器和迭代器
# 实例化模型
model = Net()
model.to(device)
# 构建损失函数
criterion = torch.nn.CrossEntropyLoss() # 交叉熵
# 构建优化器,带动量0.5
optimizer = optim.SGD(model.parameters(), learning_rate, momentum=0.5)
# 设置学习率梯度下降,如果连续2个epoch测试准确率没有上升,则降低学习率,系数0.5
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer, mode='max', factor=0.5, patience=2,
threshold=0.00005, threshold_mode='rel', cooldown=0, min_lr=0,
eps=1e-08, verbose=False
)
训练模型
model_accuracy: list[float] = [] # 每个epoch的准确率
for times in range(epoch):
# 训练
for data in train_loader:
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
# forward, backward, update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
# 测试
total: int = 0
correct: int = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1) # 从第一维度开始搜索
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Epoch: {times:>3} Accuracy: {correct / total:.4f}')
Accuracy: float = correct / total
model_accuracy.append(accuracy)
scheduler.step(accuracy) # 更新
训练结果
为了加速训练,我把这个放在 colab 上跑了,结果如下:
使用设备:cuda
Epoch: 0 Accuracy: 0.9901
Epoch: 1 Accuracy: 0.9916
Epoch: 2 Accuracy: 0.9922
Epoch: 3 Accuracy: 0.9937
Epoch: 4 Accuracy: 0.9951
Epoch: 5 Accuracy: 0.9957
Epoch: 6 Accuracy: 0.9954
Epoch: 7 Accuracy: 0.9960
Epoch: 8 Accuracy: 0.9944
Epoch: 9 Accuracy: 0.9960
Epoch: 10 Accuracy: 0.9962
Epoch: 11 Accuracy: 0.9968
Epoch: 12 Accuracy: 0.9962
Epoch: 13 Accuracy: 0.9950
Epoch: 14 Accuracy: 0.9959
Epoch: 15 Accuracy: 0.9961
Epoch: 16 Accuracy: 0.9967
Epoch: 17 Accuracy: 0.9964
Epoch: 18 Accuracy: 0.9965
Epoch: 19 Accuracy: 0.9960
Epoch: 20 Accuracy: 0.9963
Epoch: 21 Accuracy: 0.9963
Epoch: 22 Accuracy: 0.9966
Epoch: 23 Accuracy: 0.9964
Epoch: 24 Accuracy: 0.9963
Epoch: 25 Accuracy: 0.9965
Epoch: 26 Accuracy: 0.9964
Epoch: 27 Accuracy: 0.9964
Epoch: 28 Accuracy: 0.9964
Epoch: 29 Accuracy: 0.9963
Epoch: 30 Accuracy: 0.9963
Epoch: 31 Accuracy: 0.9964
Epoch: 32 Accuracy: 0.9963
Epoch: 33 Accuracy: 0.9964
Epoch: 34 Accuracy: 0.9964
Epoch: 35 Accuracy: 0.9963
Epoch: 36 Accuracy: 0.9963
Epoch: 37 Accuracy: 0.9963
Epoch: 38 Accuracy: 0.9963
Epoch: 39 Accuracy: 0.9963
Epoch: 40 Accuracy: 0.9963
Epoch: 41 Accuracy: 0.9963
Epoch: 42 Accuracy: 0.9963
Epoch: 43 Accuracy: 0.9964
Epoch: 44 Accuracy: 0.9964
Epoch: 45 Accuracy: 0.9964
Epoch: 46 Accuracy: 0.9964
Epoch: 47 Accuracy: 0.9964
···
Epoch: 97 Accuracy: 0.9964
Epoch: 98 Accuracy: 0.9964
Epoch: 99 Accuracy: 0.9964
总结与展望
本次实验实现了一个卷积神经网络(Convolutional Neural Network,CNN)对手写数字(MNIST数据集)进行分类。
主要过程如下:
- 导入需要用到的Python模块,例如
os、torch、torch.nn、torch.optim、torchvision等。 - 定义了一个名为
ResidualBlock的类,其中包含了残差神经网络(ResNet)的结构,它能够帮助模型更好地进行特征提取。 - 定义了一个名为
Net的类,其中包含了卷积神经网络的结构,它由卷积层、残差神经网络层、批量归一化层、最大池化层和全连接层组成,用于对输入的手写数字图像进行分类。 - 构建了
train_transform和test_transform对象,它们是数据预处理的一部分,用于将原始图像转换为神经网络所需的张量,并对图像进行标准化等操作。 - 定义了一些超参数,例如
train_batch_size、test_batch_size、learning_rate、epoch等,用于控制模型的训练过程。 - 加载MNIST数据集,并使用
DataLoader对象构建训练集和测试集的数据加载器,用于对数据进行批处理和随机打乱等操作。 - 实例化模型、定义损失函数和优化器,并设置学习率梯度下降。
- 进行训练和测试,并输出每个epoch的准确率。在训练过程中,首先对训练集进行批处理,然后进行前向传播、反向传播和参数更新,最后对测试集进行预测,并计算准确率。模型的训练过程在每个epoch中进行,直到达到指定的迭代次数为止。
- 将每个epoch的准确率保存在
model_accuracy列表中,并使用optim.lr_scheduler.ReduceLROnPlateau方法更新学习率,以便在模型训练过程中自动降低学习率,从而提高模型的稳定性和准确率。
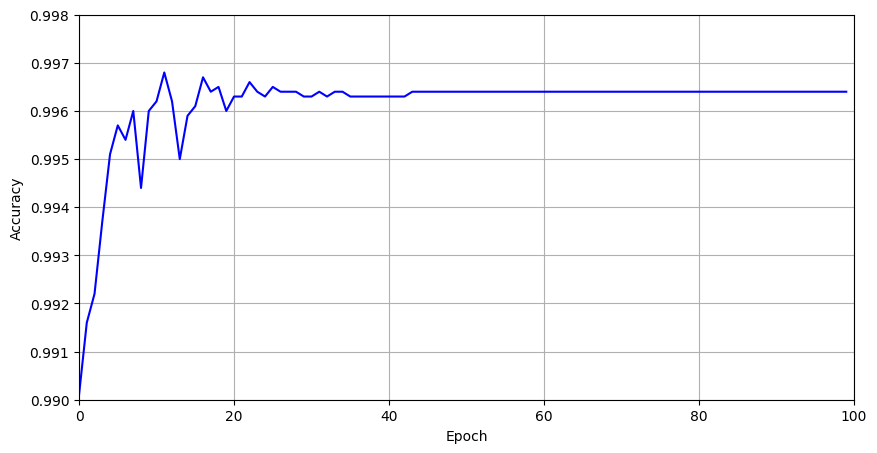
可以发现,在第 94 个epoch时,模型的准确率达到了 99.64%,并且在后续的训练过程中,准确率一直保持在 99.64% 左右,这说明模型已经收敛,不会再有太大的变化了。
最终结果达到了 99.64% ,达到了题目要求的 99.5% ,因此本次实验可以算是完成了。
由于我是先做的第二个作业,那个是手撸的,所以这个我也想手撸了,后续看看能不能搞出来吧。
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
from torchvision.transforms import Compose
import matplotlib.pyplot as plt
class ResidualBlock(nn.Module):
"""残差神经网络"""
# 需要保证输出和输入通道数x一样
def __init__(self, channels):
super().__init__()
self.channels = channels
# 3*3 卷积核,保证图像大小不变将padding设为1
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(channels, channels, kernel_size=1)
def forward(self, x):
# 激活
y = F.relu(self.conv1(x))
y = self.conv2(y)
# 先求和 后激活
z = self.conv3(x)
return F.relu(z + y)
class Net(nn.Module):
def __init__(self):
super().__init__()
# 卷积层
self.conv1 = nn.Conv2d(1, 32, kernel_size=5, padding=2)
self.conv2 = nn.Conv2d(32, 64, kernel_size=5, padding=2)
self.conv3 = nn.Conv2d(64, 128, kernel_size=5, padding=2)
self.conv4 = nn.Conv2d(128, 192, kernel_size=5, padding=2)
# 残差神经网络层,其中已经包含了relu
self.rblock1 = ResidualBlock(32)
self.rblock2 = ResidualBlock(64)
self.rblock3 = ResidualBlock(128)
self.rblock4 = ResidualBlock(192)
# BN层,归一化,使数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定
self.bn1 = nn.BatchNorm2d(32)
self.bn2 = nn.BatchNorm2d(64)
self.bn3 = nn.BatchNorm2d(128)
self.bn4 = nn.BatchNorm2d(192)
# 最大池化,一般最大池化效果都比平均池化好些
self.mp = nn.MaxPool2d(2)
# 全连接层
self.fc1 = nn.Linear(192 * 7 * 7, 256) # 线性
self.fc6 = nn.Linear(256, 10) # 线性
def forward(self, x):
in_size = x.size(0)
# channels:1-32 w*h:28*28
x = self.conv1(x)
x = self.bn1(x)
x = F.relu(x)
x = self.rblock1(x)
# channels:32-64 w*h:28*28
x = self.conv2(x)
x = F.relu(x)
x = self.bn2(x)
x = self.rblock2(x)
# 最大池化,channels:64-64 w*h:28*28->14*14
x = self.mp(x)
# channels:64-128 w*h:14*14
x = self.conv3(x)
x = self.bn3(x)
x = F.relu(x)
x = self.rblock3(x)
# channels:128-192 w*h:14*14
x = self.conv4(x)
x = self.bn4(x)
x = F.relu(x)
x = self.rblock4(x)
# 最大池化,channels:192-192 w*h:14*14->7*7
x = self.mp(x)
x = x.view(in_size, -1) # 展开成向量
x = F.relu(self.fc1(x)) # 使用relu函数来激活
return self.fc6(x)
train_batch_size: int = 256 # 训练集的batch_size
test_batch_size: int = 100 # 测试集的batch_size
learning_rate: float = 0.06 # 学习率
epoch: int = 100 # 迭代次数
random_seed: int = 2 # 随机种子
# 设备设置
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
if torch.cuda.is_available():
# noinspection PyUnresolvedReferences
torch.backends.cudnn.benchmark = True # 自动寻找最优算法
device = torch.device('cuda')
torch.cuda.empty_cache() # 释放显存
torch.cuda.manual_seed_all(random_seed) # 为gpu提供随机数
else:
device = torch.device('cpu')
torch.manual_seed(random_seed) # 为cpu提供随机数
print(f'Use device:{device}')
# 构建 compose 类的实例,包含转张量和标准化
train_transform: Compose = Compose([
transforms.RandomAffine(degrees=0, translate=(0.1, 0.1)), # 对照片进行随机平移
transforms.RandomRotation((-10, 10)), # 随机旋转
transforms.ToTensor(), # 转张量
transforms.Normalize((0.1307,), (0.3081,)) # 标准化 (均值, 标准差)
])
# 标准化 (均值, 标准差)
test_transform: Compose = Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# 加载数据集,启用了自动下载
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=train_transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=test_transform)
# 构建数据加载器
train_loader = DataLoader(dataset=train_dataset, batch_size=train_batch_size, shuffle=True, pin_memory=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=test_batch_size, shuffle=False, pin_memory=True)
# 实例化模型
model = Net()
model.to(device)
# 构建损失函数
criterion = torch.nn.CrossEntropyLoss() # 交叉熵
# 构建优化器,带动量0.5
optimizer = optim.SGD(model.parameters(), learning_rate, momentum=0.5)
# optimizer = optim.RMSprop(model.parameters(), learning_rate, alpha=0.99, momentum=0.5)
# optimizer = torch.optim.Adam(model.parameters(), learning_rate, betas=(0.9, 0.999), eps=1e-08, weight_decay=0,
# amsgrad=False)
# 设置学习率梯度下降,如果连续2个epoch测试准确率没有上升,则降低学习率,系数0.5
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer, mode='max', factor=0.5, patience=2,
threshold=0.00005, threshold_mode='rel', cooldown=0, min_lr=0,
eps=1e-08, verbose=False
)
model_accuracy: list[float] = [] # 每个epoch的准确率
for times in range(epoch):
# 训练
for data in train_loader:
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
# forward, backward, update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
# 测试
total: int = 0
correct: int = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1) # 从第一维度开始搜索
total += labels.size(0)
# noinspection PyUnresolvedReferences
correct += (predicted == labels).sum().item()
print(f'Epoch: {times:>3} Accuracy: {correct / total:.4f}')
accuracy: float = correct / total
model_accuracy.append(accuracy)
scheduler.step(accuracy) # 更新
# 绘制准确度曲线
plt.figure(figsize=(10, 5))
plt.plot([i for i in range(epoch)], model_accuracy, color='blue')
plt.ylim(0.990, 0.998) # 定义y轴的范围
plt.xlim(0, epoch) # 定义x轴的范围
plt.grid() # 显示网格
plt.ylabel('Accuracy') # 定义y坐标轴的名称
plt.xlabel('Epoch') # 定义x坐标轴的名称
plt.show() # 显示